Origins and motivation
Juridescent started as a small experiment to see what legal tech could look like when paired with modern AI. Law now sits inside a world of data and automation, so it didn’t make sense to treat it like a purely traditional field.
The rapid jump in large language models made me curious about how they would handle real judgments. I had a computing background from A levels and I wanted to see whether the same skills I used for coding projects could be pointed at law in a useful way.
People often ask why I did not just take computer science. The short answer is that I enjoy the interpretive side of law more than the mostly deterministic nature of code. I like writing code as a creative tool, not spending my life on huge databases.
One constant pain point for law students is how much case law you need to digest just to get to the point. An AI summariser for judgments felt like the most natural place to start.
I named it Juridescent, a mix of “jury” and “iridescent”.
Early sketches
I booked in to National Service about a month after finishing A levels, so the first version of Juridescent was stitched together on weekends on four hours of sleep and two cups of kopi o kosong. It did not even have a name. It lived as a small tool under my personal site that just took a PDF and spat out a wall of text.
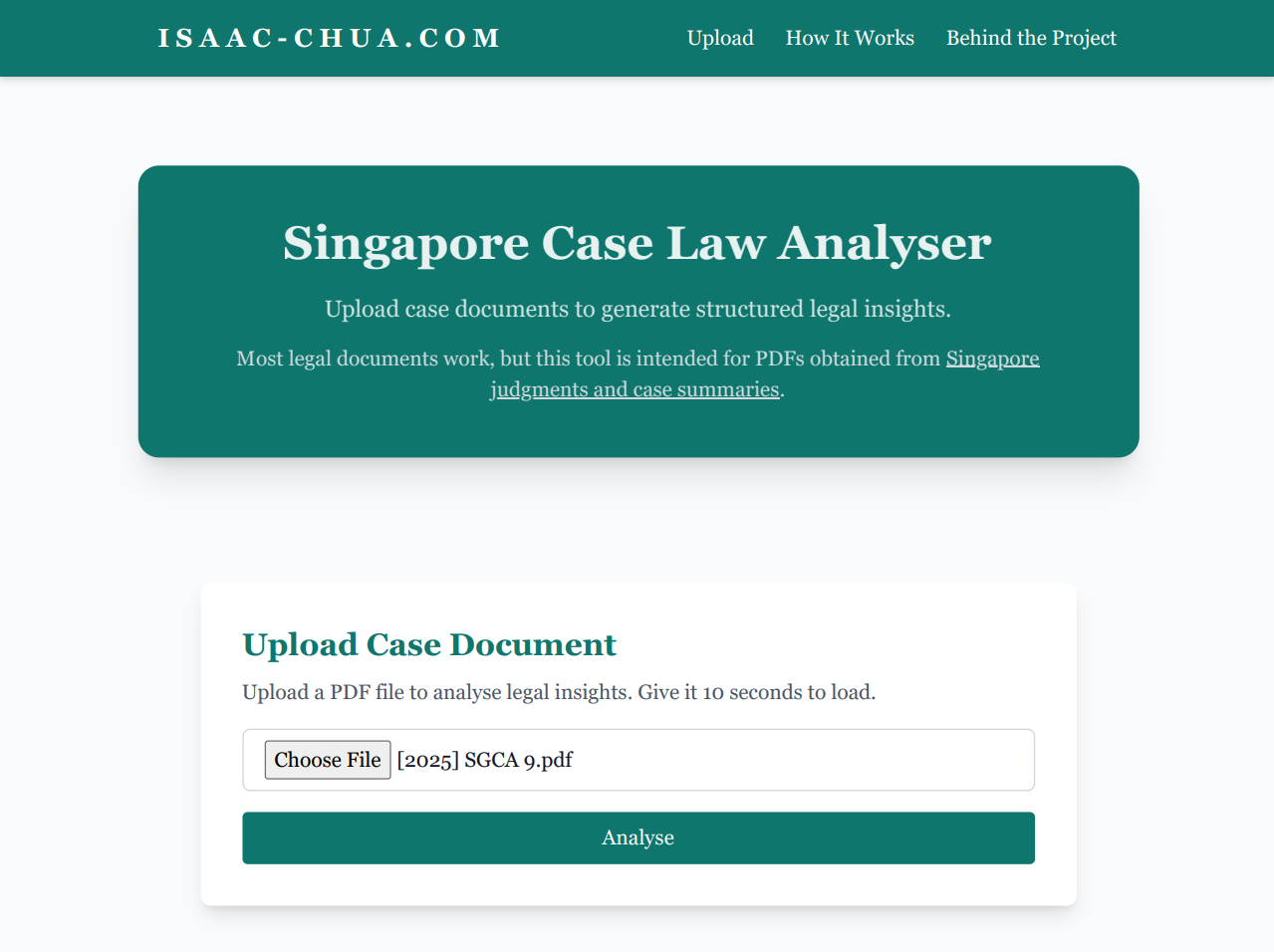
Prototype one
The first prototype had bare bones styling and a single block of summary around five hundred words. It was ugly, but it worked well enough to prove that the pipeline from PDF to summary was possible.
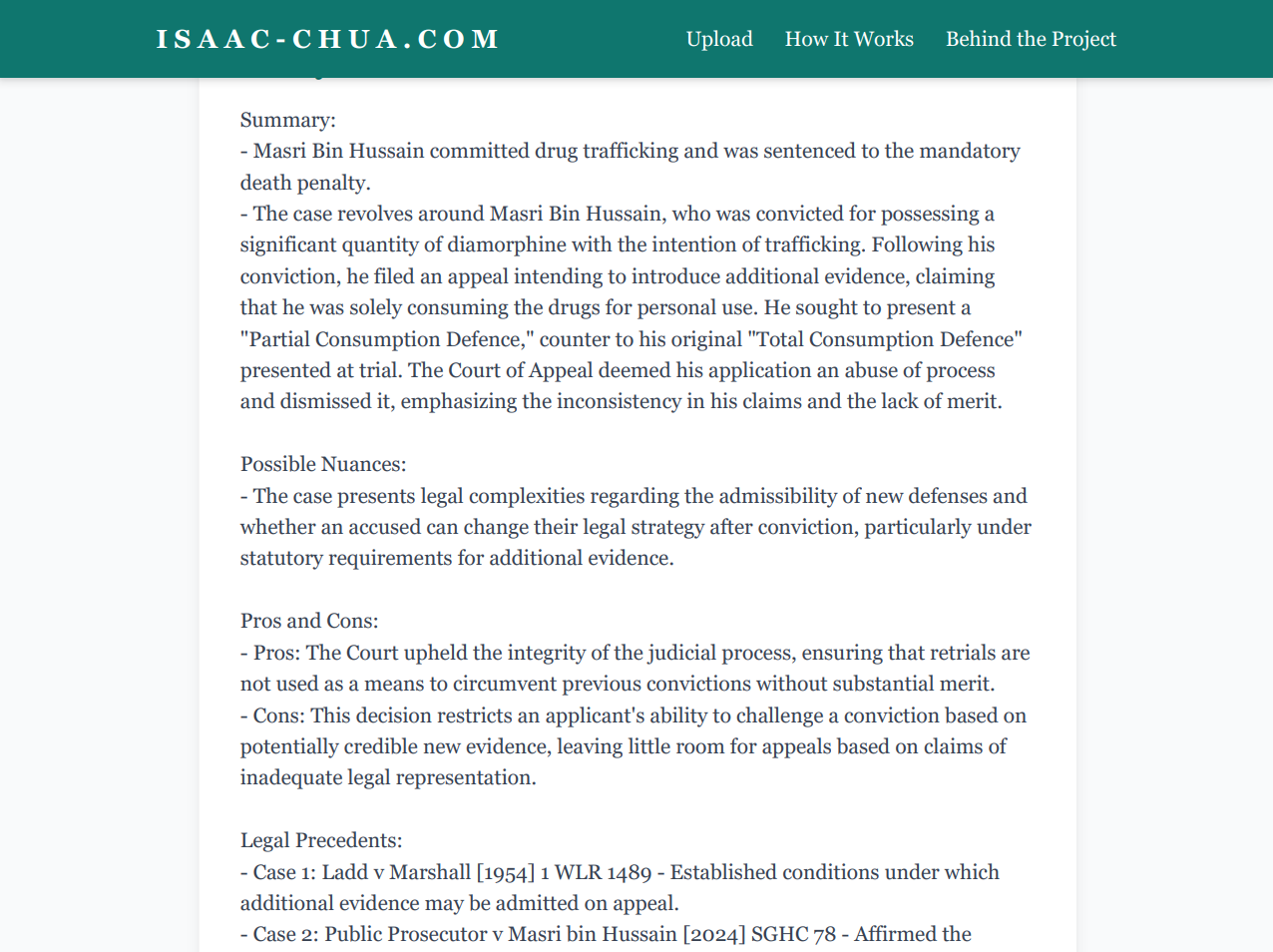
Breaking it into sections
The next step was splitting the output into separate pieces like the summary, nuances and precedents. This made it much easier to scan, even before I built the segmented cards that exist on the current site.
From blackout to blue gray
Juridescent also went through a visual reset. The earliest version sat on a pitch black background. I eventually moved to the current blue gray palette so it felt calmer and easier to live with for longer reading sessions.
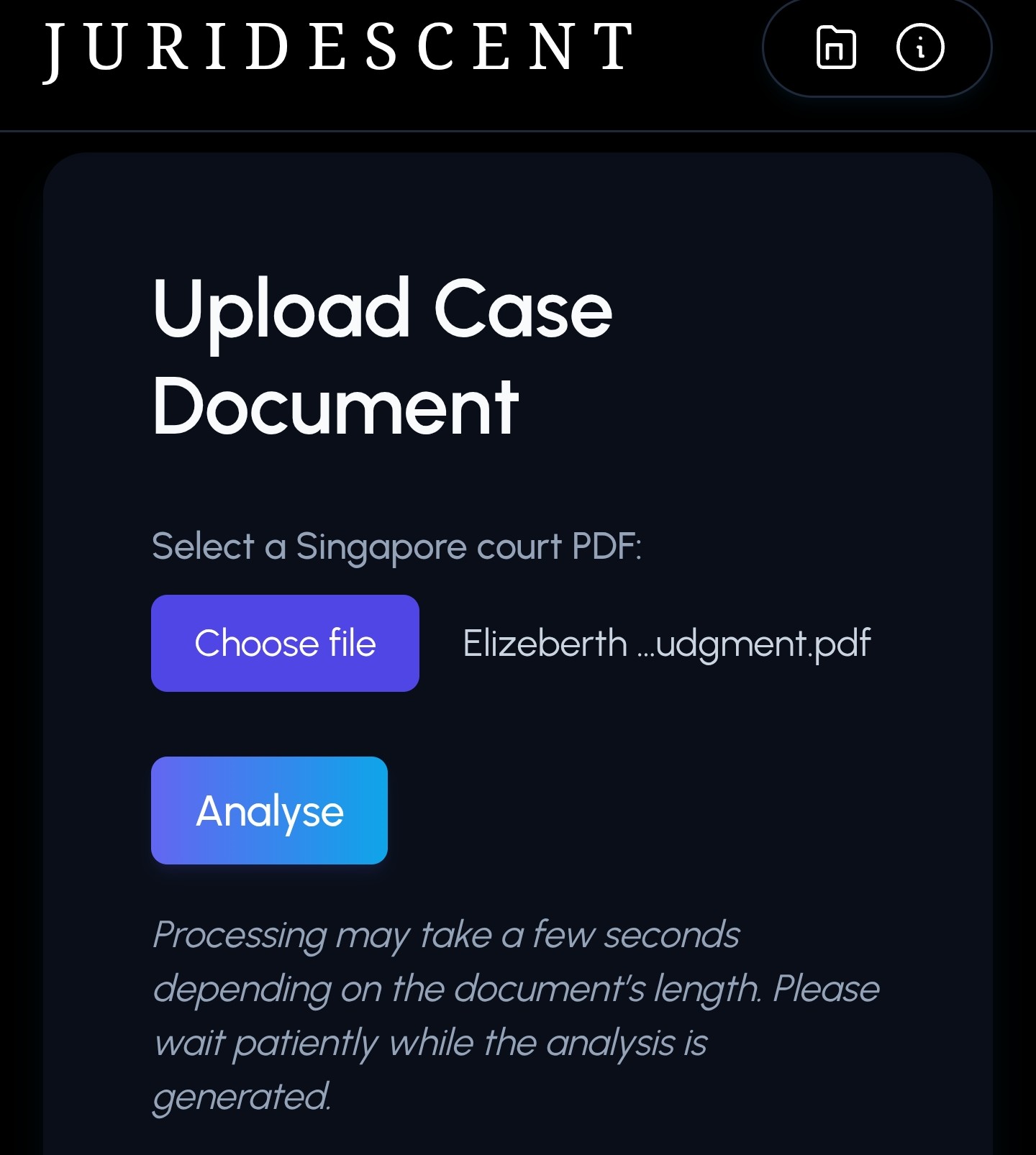
Process and challenges
On the interface side, most of the work was in making the tool feel light instead of heavy. I moved from a pure black canvas to a brighter base, swapped out the heading fonts and built separate cards for each section of the analysis so that users are not reading one endless slab of text.
When AI makes things up
The more interesting problems showed up on the AI side. At one point I fed the model a PDF of A level mathematics notes and it confidently returned what looked like a H2 math law judgment. None of it existed in the document. It was a reminder that modern models are powerful, but they still behave like black boxes that will happily hallucinate structure when you are not careful.


Tightening the prompts
To fix this I tightened the prompt engineering to check what kind of document was being processed and to push the model to refuse or qualify its output when the input did not look like a proper judgment. There is still more work to be done, but the current version is a lot more honest about the limits of what it can do.
The rest of the story is mostly technical. If you want the technical breakdown, the next sections cover how the pipeline and stack fit together.
How Juridescent works
At a high level, Juridescent takes a Singapore judgment in PDF form, cleans it up into structured text and then passes that text through a series of prompts that ask the model to think like a law student who has to brief the case. The focus is on pulling out issues, holdings and reasoning instead of rewriting the whole judgment.
Upload
You upload a Singapore court judgment in PDF format.
Analyse
The backend parses, segments and feeds the cleaned text to GPT 4o with task specific prompts.
Review
You get a structured brief with sections for the summary, IRAC, ratio and obiter, nuances and precedents.
Tech stack
Juridescent is built deliberately light so that it is easy to maintain around National Service. The stack is simple, but it does the job.
- Frontend: HTML and Tailwind CSS for a clean layout without heavy frameworks.
- Backend: Flask in Python to handle uploads, PDF parsing and calls to the model API.
- Model API: GPT 4o for turning cleaned text into structured legal analysis.
- Output: All results stay in the browser as structured sections you can skim and copy.
Interaction flow
Upload judgment
PDF is uploaded and queued for parsing.
Extract and clean
Text is extracted, line breaks are normalised and sections are stitched back into readable paragraphs.
Structured prompts
Different prompts ask the model to focus on the summary, IRAC, ratio and obiter, nuances and precedent mapping.
Rendered brief
The responses are combined into a single structured brief that appears on the Analyse page.
Future vision
For now, Juridescent is a personal experiment in how AI can support legal work instead of replacing it. I am interested in using it to test small prototypes like citation extractors, quick issue spotters and better visualisations of how precedent chains connect across cases.
Longer term, I am curious about how tools like this might plug into real student or clinic workflows. Juridescent will probably change shape a few more times before then, but that is part of the point.
Credits and acknowledgements
Built by me, Isaac Chua. ACJC graduate, NUS Law 2027. Most of this was coded during whatever free hours I had while serving with 42 SAR.
Thanks to the friends who tested early versions and pointed out weird outputs.